
Source: The Valley101
Author | Jeremy Bao Junwu Zhang Chen Qian
Editor | Chen Qian
In mid May, Tesla announced new developments in the humanoid robot Optimus "Optimus Prime" at its shareholder meeting.
In the demo, this humanoid robot can already perform a series of movements smoothly, including walking, and use vision to learn the surrounding environment; The arm strength control is very precise, and it can avoid breaking eggs; The entire palm also looks very flexible and can handle different objects.

It can be seen that Tesla's robotics development is quite fast. It should be noted that just a few months ago, during Tesla Artificial Intelligence Day in September 2022, when Musk first appeared on Optimus, the entire robot looked quite clumsy on stage, with very limited movements that could not even walk. Several people were lifted onto the stage, and the whole thing was ridiculed by the outside world.
If progress is really so fast now, perhaps as Musk said, in less than ten years, people can buy a robot for their parents as a birthday gift. With ChatGPT and AI robots, it feels like I don't have to work anymore, I can just pack my luggage and travel around the world.
However, upon reflection, it felt like the robots in Terminator were about to break free, which was terrifying. So, I am also very conflicted, just like the two factions supporting and opposing AI robots constantly fighting each other in public opinion. Do I really expect the arrival of AI robots?
However, after conducting research on AI robots, the Silicon Valley 101 team found that the ChatGPT moment for AI robots has not yet arrived.
So, in this article, let's talk about why AI robots are so difficult to do? Where has it progressed now? What are the advantages of Tesla's robots? Why did Google acquire more than ten robotics companies in history but ultimately face phased failures? Why did OpenAI abandon robot development? What progress can AI big models bring to robots today?
Definition of AI robots
Firstly, we need to define what "AI robots" are.
This concept actually has a very cool name in the academic community, called Embodied Intelligence. As the name suggests, it is artificial intelligence with a body, which is the carrier for AI to enter our physical world for interaction. However, the term "embodied intelligence" is too academic and may not be familiar to many people, so in this video, we define embodied intelligence as an AI robot.

What is the difference between AI robots and robots? Or to put it another way, what is the difference between AI robots and AI?
This picture can easily answer these two questions: robots can be classified into two categories: non intelligent robots, intelligent robots, and AI robots. There are also two types of artificial intelligence, one is in the virtual world, such as ChatGPT, and the other is with hands and feet that can interact in the real world. This picture is the track where robots and artificial intelligence intersect, which is the AI robot with intelligence, that is, embodied intelligence.
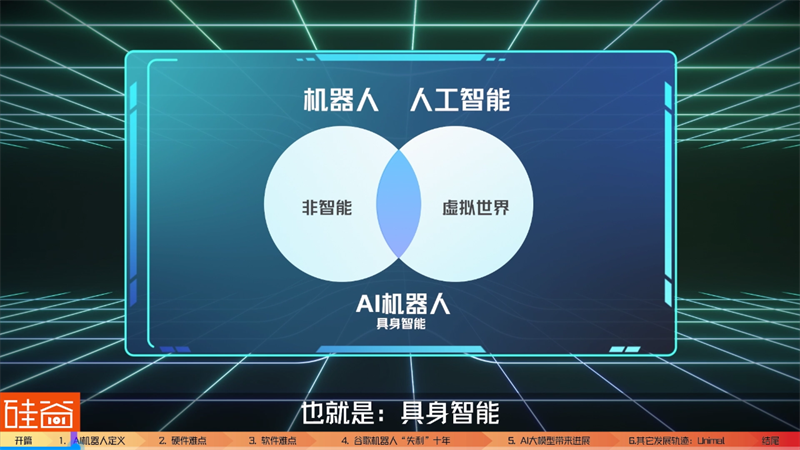
Let's give a few examples about non intelligent robots and AI robots to help everyone distinguish them.
So far, almost all industrial robots can only be programmed to perform a repetitive series of movements, which is the former. Non intelligent robots are more like machines.
In recent years, coffee robots with high traffic have been a good example. For example, there is a company in the United States called Cafe X, which uses a robotic arm to make coffee for customers. Although it may seem a bit smart, it is completely devoid of intelligence. All motion trajectories, cup position, grip strength, and the method and strength of reversing and shaking the cup are pre programmed.

那怎么才算具有智能的AI机器人呢?我们还是拿咖啡机器人举例,如果我们将机器人加上“感知”功能,比如说加上相机等视觉识别的AI算法,让这个咖啡机器人的手臂可以和外界交互,根据杯子的不同高低远近的位置,不同杯子的颜色大小,不同咖啡的品类,通过对外界“感知”而做出不同的决定,这就是AI机器人了。
再举一个非智能机器人和AI机器人的例子,也是我们《硅谷101》的AI研究小组其中一个成员之前工作过的机器人公司,那家公司研究的一个项目就是夹娃娃。
不是游戏厅的那种夹娃娃机,而是让机械手臂去分拣玩具等商品。
如果100次任务每次周围环境、障碍物都相同,而且都是把同一个娃娃从固定位置A拿起来放到固定位置B结束,那就是非智能机器人,现在已经可以做得很好了。但如果同样的100次任务,娃娃的起始位置都不同,比如说你给机械手臂一个大袋子,里面有各种不同娃娃,还得让机器人从口袋里面把特定的娃娃给识别挑出来,这就是智能机器人的范畴了。简而言之,AI算法能帮助机器人去执行更复杂的任务,让机器人从“机器”进化成“机器人”,重音在最后一个字。
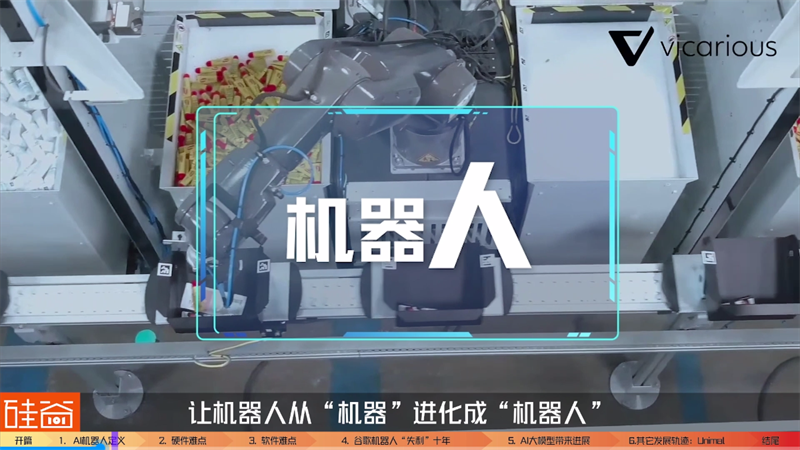
从这两个分类来看,非智能机器人已经开始了大规模的应用,包括在最新巴菲特股东年会中芒格说“现在汽车工厂里面已经有很多机器人”都是这种用来组装汽车,给车喷漆这样的非智能机器人。但对于AI机器人来说,如今还在非常早的阶段、困难非常多,连一些简单AI的机器人投入市场都接连遭遇失败。
为什么我们一定要发展具身呢?为什么AI机器人一定要有一个实体呢?这也很简单,现在无论生成式AI多么先进,都只能在电脑中帮人类完成虚拟任务,写写文件,编编程,画画图,聊聊天,就算之后有了各种API接口、AI可以进行各种软件调用,可以帮你定下机票,回下邮件,完成各种文件工作,但在现实环境中,很多问题AI还是无法帮助人类完成的。
所以,当ChatGPT引发生成式人工智能热潮之际,AI机器人赛道也迎来了非常大的关注。
包括:2022年12月13日,谷歌发布多任务模型Robotics Transformer 1,简称RT-1,用以大幅推进机器人总结归纳推理的能力;2023年3月,谷歌和德国柏林工业大学共同发布可以用于机器人的通用大语言模型PaLM-E,它和谷歌母公司Alphabet的机器人公司Everyday Robots结合,可以指导机器人完成复杂的任务;就在同月,OpenAI旗下的风险投资基金领投挪威人形机器人公司1X,总融资额2350万美元,似乎预示着OpenAI在大模型机器人应用的新布局;还有就是我们开头说到的,特斯拉也在快速发展人形机器人Optimus;同时,在硅谷,各种AI机器人创业公司也是如火如荼。

但是,虽然有了这些进展,AI机器人的研发还是非常难。除了硬件的挑战之外,还有软件和数据上的挑战。所以接下来,我们试图来解释一下,为什么AI机器人这么难。
首先来说说硬件。
硬件难点

科技媒体TechCrunch硬件领域的编辑Brian Heater曾经说过“如果硬件发展很困难,那么机器人技术几乎是不可能的。”
要理解这一层,我们首先要理解一个机器人的大致组成:
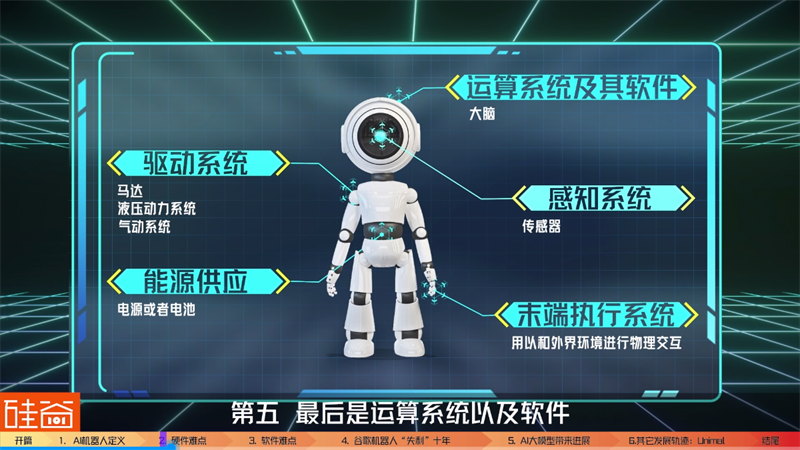
根据科技内容网站ReHack的解释,常见的机器人由5个部分组成:
1.感知系统,也就是传感器,比如摄像头、麦克风、距离感应器等等,相当于人的眼睛、鼻子和耳朵,这是机器人的【五官】
2.驱动系统,比如驱动轮子的马达、机械臂上的液压动力系统或者气动系统,相当于人的【肌肉】
3.末端执行系统,相当于人的手,它可以是机械手,也可能是机械臂上的一把螺丝刀或者喷枪,用以和外界环境进行物理交互,是【四肢】
4.能源供应,比如电源或者电池,这是【能量】
5.运算系统及其软件,将所有上面的系统整合起来,完成任务,相当于机器人的【大脑】。
前四点都是硬件的难点,第五点是软件我们下个章节来讲。
首先,机器人感知系统需要把机器人各种“内部状态信息”和“环境信息”从“信号”转变为机器人自身或者机器人之间能够理解和应用的“数据”还有“信息”。也就是说,我们要让机器人理解周围的环境。怎么做呢?
我们就在机器人身上安各种的传感器,包括光,声音,温度,距离,压力,定位,接触等等,让机器人能通过五官来收集接近人类感知外界的信息。目前,多种传感器都得到迅速地发展,但传感器的精度和可靠性依然是需要解决的难题。比如说,相机进水,进沙尘之后,或者颠簸之后相机的校准就容易失效,长期使用之后像素点就会坏死啦等等硬件问题都会直接导致机器识别的不准确。
其次,机器人的肌肉,也就是驱动系统。我们人类一共有78个关节,我们依靠这些关节来进行精准的动作,包括我们的肩、肘、腕、指。
如果要重现在机器人上,每一个关节的技术门槛和成本都很高,并且一边要求体积小、精度高、重量轻,但另外一边又要求抗摔耐撞。比如说,当机器人快速运动的时候,驱动力输出功率很高,要保证不会因为发热问题而烧坏,同时又要就具备缓冲能力,来保护“机器人关节”不怕撞击。所以,要协同这么多关节部位,还要考虑这么多因素,确实很挑战。
还有就是末端执行系统,就是“手”,这个也是非常难的,比如说机器人手指的柔软度,抓握的力度怎么协同非常重要。比如说机器人握鸡蛋这个任务,劲儿使大了吧,鸡蛋就碎了,如果劲儿小了吧,鸡蛋握不住就摔地上也碎了。
比如说波士顿动力开发的Atlas机器人,虽然可以灵活的各种跑酷,但它的手掌呢,之前的版本直接就是个球,之后变成了夹子的形状。
但特斯拉发布的“擎天柱”倒是展示出和人手非常相似的机械手,官方说,擎天柱拥有11个精细的自由度,结合控制软件,能完成像人手一样复杂灵巧的操作,并能承担大约9公斤的负重,所以在最新的demo视频中,我们也能看到特斯拉机器人在硬件上的一定优势,包括能控制力度的抓握很多物品,并且不会打碎鸡蛋。

再来说说能源供应。刚才我们说波士顿动力的Atlas机器人,虽然各种炫技动作很酷,但必须配置功率很大的液压驱动。
波士顿动力官网描述说,Atlas配置了28个液压驱动器才能让机器人完成各种爆发力超强的动作,而这样的代价是,制造成本居高不下,难以走出实验室完成商业化,所以我们看到,目标将售价降到2万美元的特斯拉“擎天柱”人形机器人后来选用了稳定性、性价比更高的电机驱动方案,也是成本考虑。
好,除了这四大块,大家是不是已经觉得机器人硬件太难了:这么复杂的系统,这么多不同的硬件,将他们整合在一起、协同工作、而且还要让合适的部位有合适的力量、速度和准确性来做需要的工作,更是难上加难。然而,机器人的身体还不是最难的。接下来,我们说说机器人的软件部分,也就是机器人的脑子。
软件难点

我们再来分拆一下机器人的软件部分:当我们给机器人一个任务的时候,比如,从一堆娃娃的袋子里去拣起其中一个特定的娃娃,机器人的软件系统一般要经历以下的三层:
第一层:理解任何需求和环境(perception)
机器人会通过传感器了解周围环境,搞明白,装娃娃的袋子在哪里?袋子在桌上还是地上,整个房间长什么样?我要去挑的娃娃长什么样子?
第二层:拆解成任务(behavior planning)和路径规划(motion planning)
明白任务之后,机器人需要将任务拆解成:先去走过去,举起手臂,识别娃娃,捡起来,再把娃娃放在桌上。同时,基于拆分好的步骤,计划好,我应该用轮子跑多远,机械臂该怎么动,怎么拿取物体,使多大劲儿等等。
第三层:驱动硬件执行任务(execution)
把运动规划转变成机械指令发到机器人的驱动系统上,确定能量、动量、速度等合适后,开始执行任务。

我们来说说这三层软件在AI上的难点。
第一层的难点在于视觉等环境识别和理解,包括识别未知物体以及识别物体的未知姿态。
比如说,机器人在识别娃娃的时候,有可能横着的时候可以识别,但竖着放、反着放就难以识别了,更别提当一个篮子里有上百个娃娃的时候,每个娃娃都有不同姿态,那就更难识别了。
第二层的难点在于AI输出的不稳定性。AI拆解任务的时候,每一次的解法可能不同,导致任务拆解不一致,这会产生意想不到的结果。这个的根本原因还是AI的黑匣子问题,我们用激励去追求输出的结果,但AI选择实现这个结果的路径可能出现不稳定性,这一点我们在《OpenAI黑手党》那个视频中也有讲。比如说,机器人从篮子的一百个娃娃中挑选出其中一个,然后放在桌上这个任务。人的路径规划是稳稳的夹起来,然后平稳的移动,然后释放在桌上,但机器人可能就甩一个胳膊直接甩到桌上去。
第三层对发展AI的悖论在于,硬件执行任务的驱动需要精准控制,而数学公式这样的100%准确率为基础、并且实现更高频运作的“控制论”更适合执行这一层任务,但目前AI做不到100%准确,速度也更慢,耗时耗力,因此,这一层对AI的需求目前并不强烈,业界还是采用的传统控制论方式。
除了这三层的AI难点之外,软件还有一大难点就是数据难以收集。而数据收集正是AI自我学习的必要条件。我们在《OpenAI黑手党》那一集中讲过,OpenAI曾经有机器人部门,但后来放弃了这条线就是因为机器人学习的数据太难收集了。
所以事实证明,只要我们能够获取数据,我们就能够取得巨大的进步。实际上,有许多领域都拥有非常非常丰富的数据。而最终,正是这一点在机器人技术方面束缚了我们。
所以,数据是人工智能的根基,就算是世界最顶级的AI公司,也会为机器人领域没有数据发愁。不管是文字、图片、视频、还是编程的大语言模型,都有全互联网海量的数据用来训练,才能在今天实现技术的突破。但是机器人用什么数据训练呢?那需要在真实世界中亲自采集数据,并且目前不同机器人公司、不同机器人的训练数据还不能通用,采集成本也非常高。
比如你要训练机器人擦桌子,人类要远程操控这台机器人给它演示,配上这个动作的文字描述,成为一个个数据点。你以为一个任务演示一遍就行了吗?当然不是,你运行的时候得从各个角度、各个不同的传感器采集数据,甚至不同的光影效果的数据也都得采集,不然你的机器人就只能白天擦桌子,晚上擦不了,左边能擦,右边擦不了。
再比如说,训练谷歌的RT-1模型用的数据集有700个任务的13万个数据点,13台机器人花了17个月才采集完,时间花了这么多,但采集的效率非常的低下。
做个对比,ChatGPT的训练数据估计有3000亿个单词,13万和3000亿,这个对比是不是太明显了。也难怪当年OpenAI放弃机器人,去All in语言大模型了,因为明显后者的数据参数更好采集。
人的交互过程中有55%的信息通过视觉传达,如仪表、姿态、肢体语言等;有38%的信息通过听觉传达,如 说话的语气、情感、语调、语速等;剩下只有7%来自纯粹的语义,所以ChatGPT这样的人工智能聊天助手能输入的部分仅占人类交互中的7%。而要让人工智能达到具身智能,那么剩下的信息,视觉,肢体,听觉,触摸等方式的数据采集,是需要给到机器人去学习的。

有没有什么低成本的数据采集方法呢?现在的做法是:在虚拟世界中训练机器人,也就是模拟,Simulation。
目前,大多机器人公司的路径都是先在模拟器中训练机器人,跑通了再拿到真实事件中训练。比如说谷歌之前的EveryDay Robots就大量运用了模拟技术,在他们的模拟器中有2.4亿台机器人在接受训练,在模拟的加持下,训练机器人拿东西这个任务,原来需要50万个数据,在模拟的帮助下现在只需要5000个数据了。各个角度、不同光影的数据也可以被自动化,不用一个一个采集了。
但是,Simulation也不是万能的解决方案,首先它本身的成本也不低,需要大量的算力支持;其次虚拟世界和真实世界依旧存在着巨大的差距,在虚拟世界跑通的事儿,到了真实世界可能会遇到无数的新问题,所以,数据收集的挑战依然是巨大的。
所以讲到这里,我们总结一下,数据采集难,三层任务AI化难,再加上对硬件的控制和整合,其中的统一性和准确性都是非常严峻的难题。在过去十年,AI机器人的发展并没有人们一度想象中那么乐观。并且,在实验室中看似已经解决的问题,到了实验室外的商用探索中,又出现了各种新的问题。
讲到这里,我们就不得不说说谷歌十年押注AI机器人但最终没能成功的故事,其实也反映了AI机器人上的发展困境。
AI谷歌十年“整合”
AI机器人的失利

在2012年前后,深度学习、3D视觉、自主规划和柔顺控制等技术的发展,让机械臂有了更好的“眼睛和大脑”,同时增加了环境感知和复杂规划能力,可以去处理更灵活的任务。
也就是我们刚才说到的第一和第二层任务上,AI在软件上的应用出现了进步。
所以在2012年,如果大家还有记忆的话(这就是一个暴露年龄的话题),一些科技巨头当时开始疯狂的收购智能机器人。比如说,谷歌在2012到2013年间,一口气收购了包括波士顿动力在内的11家机器人公司。
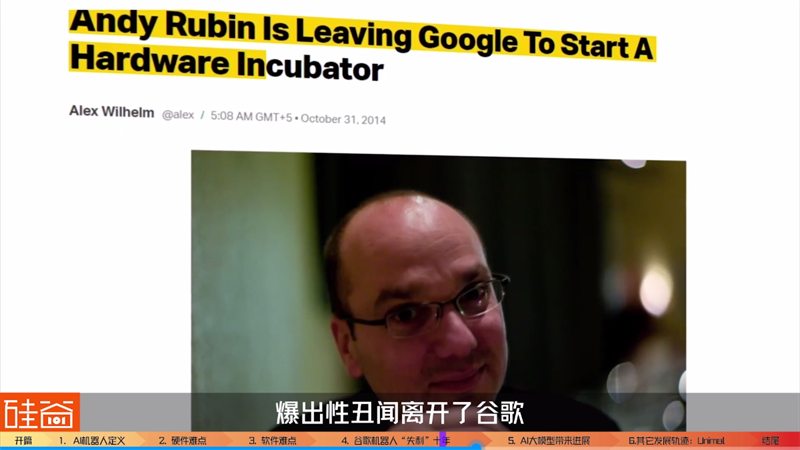
当时,谷歌内部管机器人这条件线的人叫安迪-鲁宾,是不是听着耳熟?没错,他正是安卓系统的创始人。
但同时很多人不知道的是,他还是个机器人迷,大家看安卓的英文Android这个词,英文原意就是“人型机器人”,而且安卓的标志也是个绿色的小机器人。

鲁宾从2013年就开始秘密在谷歌组建机器人部门,大家看当时他收购的这些公司,除了波士顿动力之外,还有研究双足机器人的Schaft公司,研究人形机器人的Meka Robotics,研究机械手臂的Redwood Robotics,计算机视觉人工智能公司Industrial Perception,制造基于机械臂的机器人摄影摄像系统Bot&Dolly,生产小型及全向滚轮和移动装置的Holomni公司,大家看看这些公司,谷歌显然意识到了AI在机器人中的重要性,希望结合AI推进机器人的发展。

谷歌这样的科技巨头开启收购热潮背后的逻辑可能在于:谷歌这样以软件见长的公司,在比较不擅长的硬件 以及软硬件结合的部分,是发展智能机器人难以逾越的技术壁垒。所以,我们推测,谷歌可能一度认为,在AI机器人的软件方面,因为第一层和第二层技术的进步,买来各种硬件公司整合在一起,再把软件盖在上面,AI机器人说不定就能迈出重大的进展。
经过十年的发展,当年的机器人明星公司们发现,在实际市场用途中,还远不能保证准确率和统一度。
比如说仓库分拣这个活儿,一个训练有素的工人可以达到95%的准确度,如果机器人低于这个准确率,那就意味着还需要有人来监督辅助机器人的运行,工厂老板们一算账,既要买机器人又得雇佣人类,还不如全雇人类做呢。所以机器人的准确度一般要达到95%以上甚至99%才能真正有商业价值,但现实是:如今AI机器人可以做到90%,但从90%到100%的最后10%,现在无法突破。而在这一天到来之前,机器人就很难替代人工,并且有时候还会宕机导致整个生产线瘫痪,因此客户也不愿意买单,所以准确率达不到、那么投入商用就遥遥无期,而这又意味着谷歌不断烧钱但看不到回报 。
安迪·鲁宾在2014年爆出性丑闻离开了谷歌,之后收购的这11家公司经过各种重组,有的被再出售,比如说波士顿动力被卖给了软银,然后又被卖给了韩国现代,卖给现代的时候估值只有谷歌收购时候的三分之一,还有的团队被解散,比如说Schaft公司,之后谷歌内部孵化出了两条线,致力于工业机器人软件和操作系统研发的Intrinsic以及通用机器人Everyday Robots。可惜,这两个团队都在最近的谷歌大裁员中,相当一部分人被裁掉,其中Every Robots部门不再被列为单独项目,很多员工被并入了Google Research或其它团队。我们开头举例的那个夹娃娃公司Vicarious,也因为融资不理想被谷歌收购,而很快成为了谷歌裁员的重点目标,连Vicarious的创始人都离开了谷歌。
讲谷歌失败的的机器人发展线并不仅仅是因为谷歌的办公室政治和性丑闻,而是想说明AI机器人行业发展的一个缩影:AI机器人在软件和硬件上还都需要解决的问题太多、挑战太大。
而现在,重要的问题来了,ChatGPT的出现,能否打破这个僵局呢?
最新AI热潮能带来进展

记得我们团队在跟几位从事机器人和AI工作的科学家吃饭的时候,我问了这个问题:现在这么热的AI大模型,能帮助AI机器人什么呢?其中一个AI专家说了两个字:信心。然后我们一桌人都笑翻了,虽然这是个段子,但也得到了在座专家一致的认同。
与最近爆火的生成式AI不同,机器人似乎还没有到所谓的ChatGPT时刻,很多机器人产品里都没有或者只有很少量的AI,更多是通过computer vision建立视觉,而更底层的动态规划和机械控制仍使用传统机械控制论的思路去解决,并不能算是真正有学习能力的机器人。
比如,从严格定义上来看,大名鼎鼎的波士顿机器人公司似乎就不是一个AI驱动的公司,更像是个传统机器人公司,特别是,他们的AI研究院在2022年才成立。
但一个积极的现象是:各家机器人公司对AI的整合都越来越多,搭载了更多AI的机器人也更受到资本的青睐。比如我们在《OpenAI黑手党》那期节目提到的Covariant公司,他们工业机器人的主打卖点,就加载了预训练的AI模型,可以在没有特别训练的情况下就执行货物分拣任务,分拣的东西变化了之后也可以自主的适应。
如今,现阶段大模型对机器人的应用大多停留在科研阶段,还非常早期。其中,AI大模型无法在根本上帮助具身智能的一个原因在于,大模型提高的是通用性,而AI机器人需要解决的问题是准确性,这个钥匙和锁对不上。很简单的一个例子:如今像ChatGPT这样的大模型的准确度,在一些领域上,有时候还没有经过了充分训练的小模型的准确度高。ChatGPT能通用地回答各种问题,但它的回答不免出现常识错误,我们可以对这些错误一笑而过;但如果同样的事情发生在机器人上,带来的可能就是停工停产,经济损失,甚至更严重的事故。
但是,尽管如此,从未来前景来看,大模型还是能给机器人领域带来一些的正面推动的:
首先,在自然语言交流上,我们再回到机器人软件的三层模型来看,谷歌发布的拥有5620亿个参数的多模态视觉语言模型Palm-e主要解决的是第一层及第二层的部分问题,因为这一部分之前要靠编程来告诉机器人怎么做,而现在机器人可以听懂自然语言,并将自然语言任务直接拆解成可执行的部分。

同时,在2023年4月初,Meta发布了名为Segment Anything的通用AI大模型,简称SAM。我们《硅谷101》音频的嘉宾Jim Fan在聊SAM的这一期节目中称“SAM是图像识别领域的‘GPT时刻”,因为SAM使得计算机视觉可以分割一个从未见过的物体。而这会在第一层软件上为视觉识别带来非常大的帮助。
其次,像谷歌的RT-1主要解决的是三层模型中的第二层问题,也就是如何将任务和环境信息转化成动作规划。研究人员发现,在Transformer大模型的加持下,机器人执行从未做过的任务的成功率明显上升,对不同环境甚至有干扰情况下的成功率也有上升。这是迈向通用机器人的重要一步。也就是说,机器人可以执行之前从未执行过的任务了。
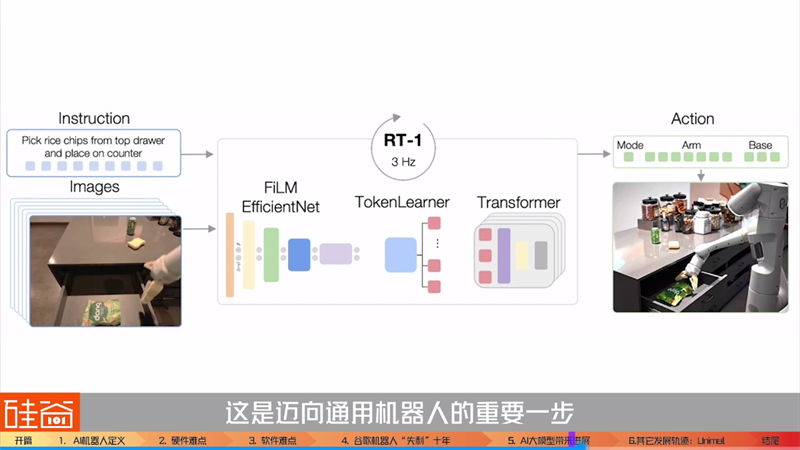
再者,在数据上得到提升。在RT-1中,研究人员使用了不同型号的机器人的数据来训练模型,结果发现自己机器人执行任务的准确率提升了。虽然这方面的研究还比较早期,但如果未来有大模型能使用不同机器人的数据进行预训练,可能会进一步提高准确度,那么这意味着,机器人AI的通用训练集也能实现了。
这几个进展是目前的大模型热潮除了给AI机器人赛道带来“信心”之外,还切实带来的进步,但即使如此,我们现在还在非常非常早期的阶段。也有业内人士告诉《硅谷101》,虽然这四个模型的发布振奋了AI机器人市场的热情,但Palm-e和和RT-1的技术对于行业来说都不是全新的消息,因此,这四个模型能如何赋能AI机器人,还需要我们进一步去验证。
另外,虽然特斯拉最新发布的视频没有对Optimus做任何技术上的解析,但马斯克透露,特斯拉已经打通了FSD和机器人的底层模块,实现了一定程度的算法复用。我们知道,FSD算法指的是特斯拉全自动驾驶,是Full Self-Driving系统的缩写。FSD的这个算法让车辆可以实现自主导航和自动驾驶功能,包括让车辆能够在各种交通环境下进行感知、决策和控制。如果,这一套基于神经网络和计算机视觉的技术算法也可以移到AI机器人上,相信会对软件方面帮助不少。
但是同时,我们还想强调一点,在AI机器人流派中,还有很多其它的尝试正在进行,不一定大模型神经网络能够成为具身智能的解药,大模型也不一定是我们能达到通用人工智能的解药。我们今天讲述的具身智能发展派的做法是在人工智能上将软件和硬件分开各自迭代,然后将两者融合的方式去做AI机器人。但目前学术界,也有一些新的流派在产生,认为人类现在训练具身智能的方式还只是单纯的输入的输出,但是,具身智能也许需要更加多通道的全面的跨模态交互,因为这样的行为交互才最能体现机器对环境的认知试探和反馈,才能在和环境的互动过程中学习和成长。
其他发展轨迹:Unimal

比如说,斯坦福人工智能实验室前主任李飞飞博士在2021年提出了DERL的概念,是Deep Evolutionary Reinforcement Learning 深度进化强化学习的缩写,这是一种非常新的发展具身智能的思路。

与其人们设计出具身智能的最终形态身躯再强加上AI软件来驱动,李飞飞博士提出,智能生物的智能化程度,和它的身体结构之间,存在很强的正相关性,不如让AI自己选择具身的进化。而这样的具身不一定是人形机器人。也就是说,对于智能生物来说,身体不是一部等待加载“智能算法”的机器,而是身体本身就参与了算法的进化。
李飞飞博士说她通过回溯5.3亿年前的寒武纪生命大爆发找到了灵感,当时,许多物种首次出现。如今共识的科学理论认为,当时新物种的爆发部分原因,是由眼睛的出现所驱动的,视觉让生物们第一次看清楚周围的世界,而通过视觉,物种的身体“需要在快速变化的环境中移动、导航、生存、操纵和改变”,从而自行进化。
也就是说,地球上所有的智力活动,都是生物通过自己的身体,真真切切地与环境产生交互之后,通过自身的学习和进化所遗留下来的“智力遗产”。那么,具身智能,也就是AI机器人,为什么会是一个例外呢?为什么不是自己进化,还是让人类设定最终形态呢?
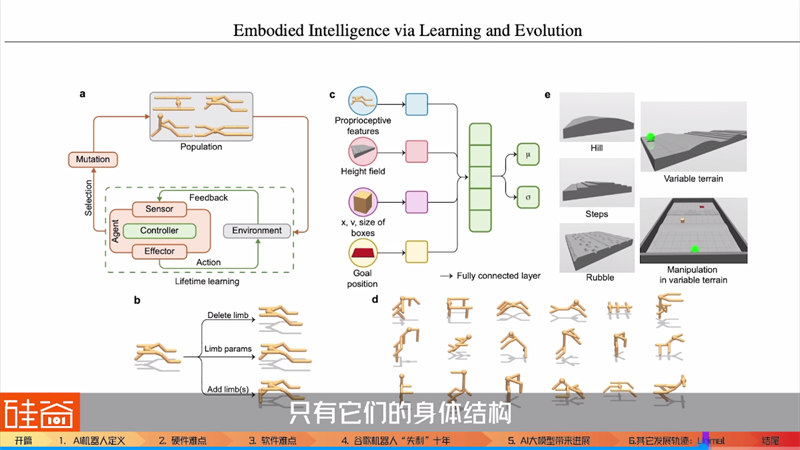
所以,李飞飞博士在这个DERL,也就是深度进化强化学习的论文中,提到了生物进化论与智能体进化的关系,并且借鉴了进化论的理论,制造了一个假设的智能体,名为“Unimal”。

就是图中身上长满了小棍的这个东西,是universal和animal拼起来的一个词,然后规定了模拟环境的虚拟宇宙中的三条规则:
第一条规则:这个宇宙中存在大量的虚拟生命agents,这些agents的具身,就是这些像小棍一样的肢体和头部拼接起来的虚拟生命。这些具身代表着不同的基因代码,模拟出不同环境下进化出的不同具身。大家可以看到,平地,崎岖不平的山路,和前面有障碍物的环境下,具身会进化出不同的结构,有的像八爪章鱼一样,有的像小狗一样的四足结构,反正就是非常不一样。
第二条规则是:这些形态各异的虚拟具身,都需要在自己的一生中,通过使用机器学习算法来适应不同的环境,比如平坦的地面、充满障碍的沙丘,在这些环境中完成不同的任务,像是巡逻、导航、躲避障碍物、搬运箱子等等。
第三条规则是:通过一段时间的学习训练之后,虚拟具身之间要相互比赛,只有表现最突出的一部分能够被保留下来。然后,它们的基因代码经过相互组合之后,产生大量新的身体结构,再重复第一和第二条规则中学习适应各类环境和任务的过程。
要注意的是,上一代虚拟生命遗留给下一代的,只有它们的身体结构,而不包括它们在一生中学习到的经验和算法。
通过搭建这样一个虚拟宇宙,研究人员在里面使用各种条件,对上千个具身形态进行了严酷的筛选。最终发现:一个物种在前几代通过长期和艰苦的深度学习获得的行为,在后几代中会变成一种类似本能的习惯。
如说,某个具身的祖辈花了很长时间才学会跑步,但是在经过几代进化之后,它们的后代生下来没多久就自己会跑了。
李飞飞团队的研究人员说,在学习和进化的双重压力下,最终只有那些在结构上有优势的身体结构,才能够被保留下来,进行进化。这些结构由于可以更容易学习到更先进的算法,于是在每一代的竞争中就积累下了大量的优势。研究人员把这种身体结构上的优势叫做“形态智能”。在算力相同的情况下,具备形态智能优势的生物可以更快获得学习上的优势,从而赢得残酷的生存竞争。这其实是验证了19世纪末著名的“鲍德温效应”。
所以,这篇论文得到的结论是,DERL深度进化强化学习使得大规模模拟成为现实,通过学习形态智能的进化过程可以加速强化学习。而李飞飞博士也表示:“具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能”。也就是说,将进化论放进人工智能领域,用“具身智能”而非纯粹的“算法智能”,来加快人工智能机器人的进化速度,也许是能更快推进具身智能前进的方式。
目前,研究依然还是非常早期的阶段,所有训练也还只在的模拟器中,但这已经让之后的具身智能发展充满了各种悬念:最终出现在我们面前的具身智能,可能不是我们想象中的机器人形态,更有可能是一种浑身插满各种木棍儿的小人也说不定。
所以,我们这个视频在结尾得到的结论就是:AI机器人,也就是具身智能的发展,没那么容易。这个赛道还没有等到自己的ChatGPT时刻,我们开头描述的那些场景距离实现还早着呢,所以大家既不用担心终结者很快到来、也不用兴奋很快会有AI机器人能帮我们去遛狗排队买咖啡。
但是,具身智能的出现,是“机器人”Robot这个词最开始发明的时候,就在人类的想象中的。
大家猜猜英文Robot是怎么来的?
这个词最早其实出现在1920年捷克文学家卡雷尔·恰佩克的三幕剧《罗素姆万能机器人》(Rossum's Universal Robots),而Robot这个词源于捷克语的“robota”,意思是“苦力”和“奴隶”的意思,之后成为了机器人的专有名词。
而这个三幕剧讲的什么故事呢?
这个故事讲述的是,罗素姆这个工厂大规模制造和生产机器人,本来初衷是完成所有人类不愿做的工作和苦差事,从而解放人类投身于更美好、更高的事物。但后来,机器人发觉人类十分自私和不公正,终于造反了,因此消灭了人类。但是,机器人不知道如何制造自己,认为自己很快就会灭绝,所以它们开始寻找人类的幸存者,但一直没有找到。最后,一对感知能力优于其它机器人的男女机器人相爱了。这时机器人进化为人类,世界又起死回生了。
100多年前,机器人Robot这个词诞生的时候,小说家卡雷尔·恰佩克似乎就觉得终有一天,具身智能会来到人类世界,并且和人类的关系变得破朔迷离,机器人可以消灭人类,也可以进化为人类。我不知道是否有一天,这个幻想的故事会真实抵达我们的世界,但稍微能安抚大家的是,至少在现在,我们依然距离这个故事还很遥远。
注:*本文(含图片)均为转载,若有侵权请联系删除。





